
Introduction
Pandas is an incredibly powerful library for data analysis. We can use Pandas to effectively get an initial snapshot of our data and explore it for features, and insights. It is sometimes confusing to understand the use of 2 key methods on a pandas DataFrame - iloc and loc. This article will clear this up so you can use them easily on to select, filter and sort your data.
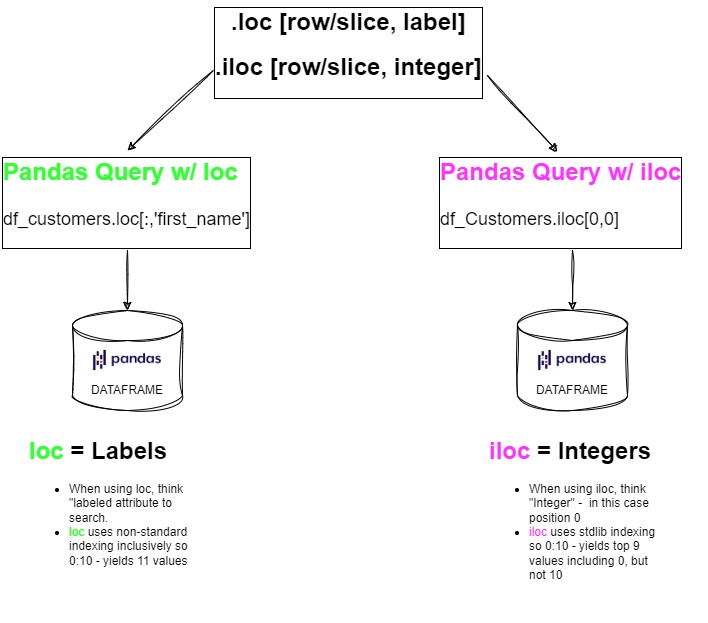
Why use these methods?
When we learn SQL, our most basic method to query data is the SELECT statement. This allows us to query for specific data in a table. In essence, Pandas DataFrame acts like a table and we use loc and iloc to query the table.
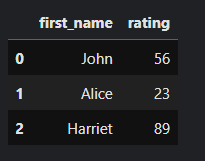
Lets review a very simple 3 X 2 pandas dataframe of customers and ratings called df_customers:
Let’s create the dataframe:
python import pandas as pd
customers = ['John', 'Alice', "Harriet"]
rating = [56, 23, 89] df_customers = pd.DataFrame({'first_name':customers, 'rating': rating})
Key points about loc and iloc:
iloc takes 2 parameters - [rows, columns]
- Rows is a single integer or slice representing the rows of our query
- Columns represent the columns we want to include
- iloc uses number indexes for both rows and columns - let’s look at some examples:
df_customers.iloc[0:10, :] # returns the first 10 rows, from index 0 to 9 df_customers.iloc[0,:] # returns first row, all columns - John, 56
df_customers.iloc[0,0] # returns first row, only first column - John
df_customers.iloc[:,:] # returns all rows and all columns - this will be the original source dataframe
df_customers.iloc[0:1, 0] # returns record 0, first column - John
Bear in mind that iloc uses standard indexing scheme - So
0:10- will include records from index 0 to 9, but not the record at index 10
loc also takes 2 parameters - [rows, columns]
- The key difference with loc is that it enables a few different use cases:
- Filtering columns and rows with label names of the dataframe (i.e. ‘first_name’, ‘rating’)
- Filtering rows with labels/attributes or indexes - These labels can be of various types, including integers (which might look like positions but are actually treated as labels), strings, or other objects.
.locdoes not use integer positions in the same way that.ilocdoes. - Selecting rows using conditions
df_customers.loc[:, 'rating'] # all rows, only the rating column
df_customers.loc[df_customers['first_name'] == 'John', ['first_name', 'rating']] # rows where first_name is 'John', columns 'first_name' and 'rating'
df_customers.loc[0, :] # first row (assuming default integer index), all columns
df_customers.loc[df_customers['rating'] > 50, :] # rows where rating > 50, all columns
Bear in mind that loc does not use a standard indexing scheme - So
0:10- will include records from index 0 to 10, but will include index 10, resulting in 11 records returned
python df_customers.loc[0:10, :] # returns rows from index 0 to 10, inclusively
Conclusion
Understanding the difference between loc and iloc is crucial for effective data manipulation with Pandas. When using iloc think i = integer based indexing while loc is label-based indexing. I highly recommend spinning up a
Kaggle Notebook and trying out these examples!